Chapter 15: DNA Tangling
Why is the genetic code written in strings?
The text you are now reading is one-dimensional — the information that this line of text carries does not depend on its position relative to the line above or the line below. You could cut the page into strips, each containing one line, and paste them end to end – it would read the same. Images, figures, are essentially two dimensional – cut the image on the cover of a magazine into strips: it would make no sense at all. In this sense the building blocks of life: DNA, RNA, and proteins (at least initially), are really the building strings of life, and we can ask: why? In Candide, Voltaire warned us that it is unlikely that this is the best of all possible worlds: things could be otherwise. The genetic code could be dimensionally otherwise, but there is a reason why it isn’t.
Let’s begin with the premise that the code must be made out of physical stuff, and that it must be replicated locally, where local replication means that each letter in the code is copied next (close in physical space) to the original. Our choices for the dimension run between zero and three; zero because it is hard to imagine what negative dimensions are, and three is the apparent physical maximum if we assume the code does not depend on time. A zero dimensional code would have no continuity and therefore no order – you could think of a bag of Scrabble letters. There may be information in the letter distribution – how many of each letter you have, but you don’t know which letter comes after which. This is inefficient – a great deal of information can be kept in the order itself. A randomly ordered collection of the words on this page wouldn’t tell you as much as much as the page does now, I hope. Three dimensions presents problems in replication. This is an age-old challenge in manufacturing — in order to build an object we have to break it down to a set of pieces that are in a sense at most two-dimensional. You can make, say, a solid cube with a mold, but if the cube were truly three dimensional, in the sense that the inside of the cube might be different than the surface, a mold isn’t going to do it. You can’t determine interior detail with a mold. The problem is roughly this: a three dimensional object takes up all of physical space, so there is nowhere, locally, to replicate to.
Many things seem to have a fractional dimension. For example, an irregular coastline is often modeled as having dimension between one and two. These constructions require a kind of infinite division, so it is not clear what use fractal dimensions would be in this case. Quantum mechanics tells us that there is some small informational unit we cannot subdivide, so we would have to use quasifractals in any case — that is, the fractal nature would only become apparent as our information storage and replication device became very large. Now it is true that a cell’s worth of DNA is very large relative to a single base pair, but here we will concern ourselves with the local dimension, and so only consider integer dimensions.
We are then left with two options: one dimension or two dimensions.
It is common knowledge that the eukaryotic chromosome is a marvel of string compaction. The DNA is supercoiled, wrapped around the nucleosome core, like thread on a spool, the spools are packed together in the 30nm fiber, which is then looped and the loops made into rosettes, the rosettes combined into coils, and the coils together make up the chromotids. It’s a long string in a small space, and as such it is subject to one of the fundamental laws of nature: long strands in small spaces tend to become entangled.
Then there is the replication. The way DNA works is that it unzips along the strand like an incredibly long zipper. As the unzipping happens, new acids are added to the open teeth of two strands of the zipper, so that those two strands each become complete zippers on their own.
But if the original zipper was tangled, when we locally replicate this way, topology tells us that the result is a pair of strands that are entangled with themselves and with each other. How are they going to separate for the cell division?
Not only is the DNA tangled because there is so much of it packed in a small place, but the unzipping itself can be problematic. DNA of course has the double helix structure — the zipper is twisted. So when it is unzipped, that twist contributes to the tangling as well.
And there is an additional way we get tangling. DNA lives in a volatile environment — free radicals shoot through at regular intervals, causing breaks in the string that need to be repaired. Since there is so much length packed in, sometimes these repairs induce tangling — there can be mis-repairs, where the wrong open ends are joined, and even if the original order is restored, other strands may have passed through the break room while it was open.
Thus we should not be surprised that the tale of compaction is also one of tangle management. One effect of supercoiling is to stiffen the strand, making it less likely to tangle. Since supercoiling is itself a kind of tangling, this is a tradeoff – a controlled, manageable tangling is induced to reduce random entanglement, sort of like braiding hair. The length wrapped around a nucleosome, 146 base pairs, might be about as much as you could let flop around without getting tangled. Each level of compaction is also a method of restricting random motion of the strand, like wrapping the last foot or two tightly around a coiled extension cord.
In order to relieve this tangling, the system has evolved various topoisomerase enzymes, which can cut DNA strands and pass other strands through, or allow the strand to unwind a bit, and then rejoin the open ends. This is as if you untangled your extension cords with scissors and tape. It has the advantage that you don’t have to to pull the strand all the way through the tangle to effect the untangling, which is a tough thing for a single enzyme to do in the DNA case. On the other hand, your extension cord would stop working pretty quickly.
So dimension one presents some serious design and execution challenges. The other alternative, dimension two, a surface, has a great deal to recommend it. Information arrayed on a surface, like words on a page, is accessible from the half space on either side, and so is easy to replicate. Consider one of our best replicators, the copy machine. Here the information is replicated along a one-dimensional front — the light bar you see processing underneath the glass if you copy with the cover open. It is pretty easy to imagine a two-dimensional genetic code. It could be two ply, like a paper towel. Replication would consist of peeling the two plys apart, while matching elements attach to make each daughter ply half of a new two-ply towel, which would then peel apart, and so on. Note that in the peeling apart, the replication would be proceeding along a one-dimensional front, just as it does with the copy machine. Moreover, a surface is far less likely to have the entanglement problems that a filament has. You can roll up a section of a plane, as we do a rug, which compactifies it quite a bit. You could also fold it accordion style. Of course, some two-dimensional shapes would have topological obstructions. You could not, for example, lift a surface off a sphere without cutting along a seam – though you could have enzymes that cut the genetic fabric. A finite cylinder would have no such obstruction — the replication front would be a circle around the tube that processed along the length of the tube.
Another advantage of a two dimensional informational array is an extra dimension of local information for error checking — that is, we can require consistency up and down as well as left and right. Damage repair would be much easier – those rampaging radicals would poke holes, not cut strands, and the holes would be easy to fill and there would be no chance of joining the wrong open ends, as happens with strings. In fact these string misrepairs are believed to be a cancer mechanism.
So two dimensions seems to be preferable, on grounds of both ease of replication and of replication fidelity. But nature has chosen one dimension. Why? The answer can be seen in our own information processing activity. For all of our fascination with images — photographs, paintings, graphs, movies — the greater part of our information manipulation is in one-dimensional forms: text, speech. This is for a pretty simple reason. It is much easier to edit in one dimension than in two. And this is for a pretty simple mathematical reason.
What is editing? Editing consists of making new boundaries by cleaving sets of code, then aligning the boundaries in a new pattern. The boundary of a set is of dimension one less than the set itself. So, for a one dimensional set, a string, the boundary is zero dimensional – the two endpoints. Think of how easy it is to cut and paste in a word processor – you simply place one boundary next to another. You can paste a novel into the middle of a sentence if you want to.
For example, if we start with the sentence:
I wish I had written that.
We can edit it to:
I wish I had written “It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief…(140,000 words)…It is a far, far better thing that I do, than I have ever done; it is a far, far better rest that I go to than I have ever known” that.
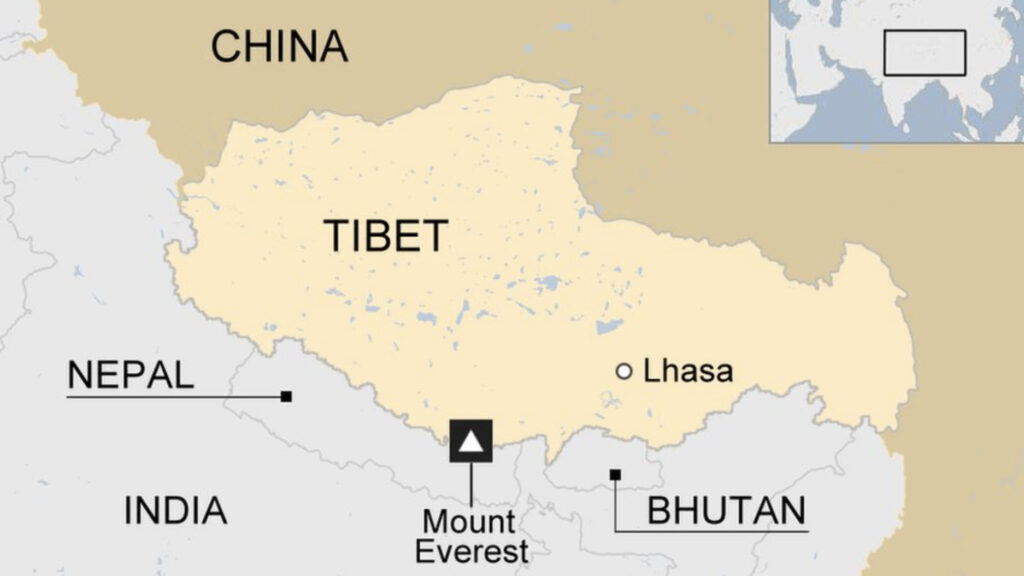
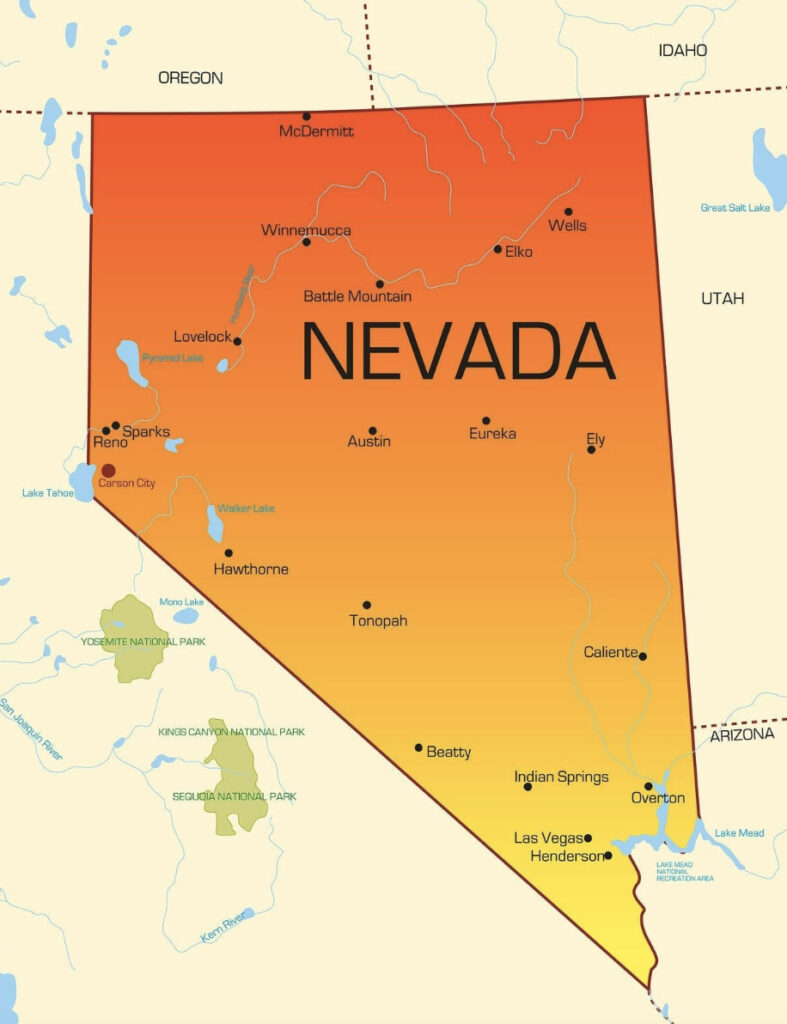
Compare this with editing in two dimensions, say with image processing software such as Photoshop. To change any section of the image you must deal with the boundary of that section, which is one dimensional. Another boundary is not likely to match up. For example, let’s say you have devised an imaginary world where the dusty desert and thirsty cowboys of the American southwest have been replaced with mountain dwelling monks, so on the map you need to replace Nevada with Tibet. But you cannot simply replace one region with another (paste Tibet into Nevada) – their boundaries (borders) will not align. To paste an arbitrary region into another arbitrary region, you generically need to scale and distort to have the boundaries match (this is one reason image editing is so time consuming). With a boundary (border) of any length, this is very unlikely to happen by chance.
Which brings us to evolution. The general idea of evolution is that our code will undergo random edits, and that natural selection will choose the edits that are beneficial. The problem with a two dimensional information array is that almost no random cuts can become completed edits, so evolution will be very slow if it happens at all.
So the editing capabilities in one dimension make it much easier to make new from old, so a system based on one dimensional information would evolve much faster than a two dimensional one — two dimensions has too much fidelity, because of the difficult to satisfy requirement of boundary consistency.
This also means modular evolution is very unlikely – where by modularity we mean the fitting together of two sections, each of which do something successful. In fact any kind of evolution driven by random mutation will be very slow if it is possible at all.
So two dimensions would be the place to be if we were sure we had the final design, and were not interested in any further adaptation. But in the competitive, dynamic world we live in, one dimension is the way to go.
We discuss elsewhere that the difficulty of folding putting a limit on the length of proteins – kind of interesting, which of course is related to the notion that entanglement of DNA and RNA can be a limit on complexity. In fact this note is in some sense the first chapter in this book.
As anyone who has written a scientific paper knows, figure preparation can be a deep time sink indeed.
So one dimension appears to be the best choice — assuming you have to make a choice. You might notice that our choices actually vary with the context — sometimes we prefer a picture or a movie, sometimes text or audio. But most of our information at some point passes through a one-dimensional conduit — in a sense photography lost its distinctive two-dimensional character when the process became digitized. Still, it might be interesting to know what the average dimension of our information experience is. The front page of the average newspaper, print or digital, is perhaps sixty percent text and forty percent image?
(We wonder if in general text is more adaptable than images… seems so… what is changing font?… we often translate text into the language of a new time or land…but the image is more often brought whole if at all…)
Finally, you can always build up dimensions, that is, you can create or describe two and three-dimensional objects with one-dimensional information, so you haven’t lost descriptive power by using one dimension. I can, for example, say the words ‘a solid sphere’ and you know the three dimensional object I refer to. If you want a more precise description, I can give you directions on how to make a ball of string. If you want the actual object, I can hand you the ball of string. Similarly, DNA contains many one-dimensional descriptions of proteins, which, once folded, will take on three-dimensional shapes.
The DNA complex is nature’s solution to a problem we face in many contexts in the digital world: how to fit a lot of information into a small space. Given the length of the code in the cell, this is a tangle management problem of monstrous proportions
One way to address tangling is to try to prevent it from happening in the first place. Tangle management is one of the driving forces behind the design of the DNA.
It is at least dimension one, since it is a continuous curve, but it is so wrinkled that it in a sense takes up room on the map, so it is thought of as between dimensions one and two.